
Claude vs GPT vs Gemini en 2026: Comparativa, Benchmarks y Cuál Es Mejor
📅 Actualizado: 30 de junio de 2026 · Próxima revisión: julio 2026
En 2026, los tres grandes de la IA generativa —Anthropic (Claude), OpenAI (GPT) y Google (Gemini)— están técnicamente empatados en lo más alto, y el "mejor modelo" depende de la tarea: Claude Opus 4.8 lidera el código difícil y los agentes (SWE-bench Pro 69,2%), GPT-5.5 y Gemini 3.1 Pro empatan en razonamiento y ciencia (GPQA ~94%), Gemini domina lo multimodal, y Claude Sonnet 5 ofrece la mejor relación calidad/precio (2-3 $ por millón de tokens). Para una empresa, la conclusión práctica es que elegir "un único modelo" es la decisión equivocada: lo rentable es una plataforma multi-modelo que use cada uno donde gana. Abajo tienes la comparativa con benchmarks reales, precios y una guía de qué usar para cada caso.
¿No sabes qué modelo poner en tu empresa? No tienes que elegir uno: te monto una plataforma que usa el mejor de cada momento para cada tarea. Cuéntame tu caso → Hablemos →
TL;DR — Quién gana en qué (2026)
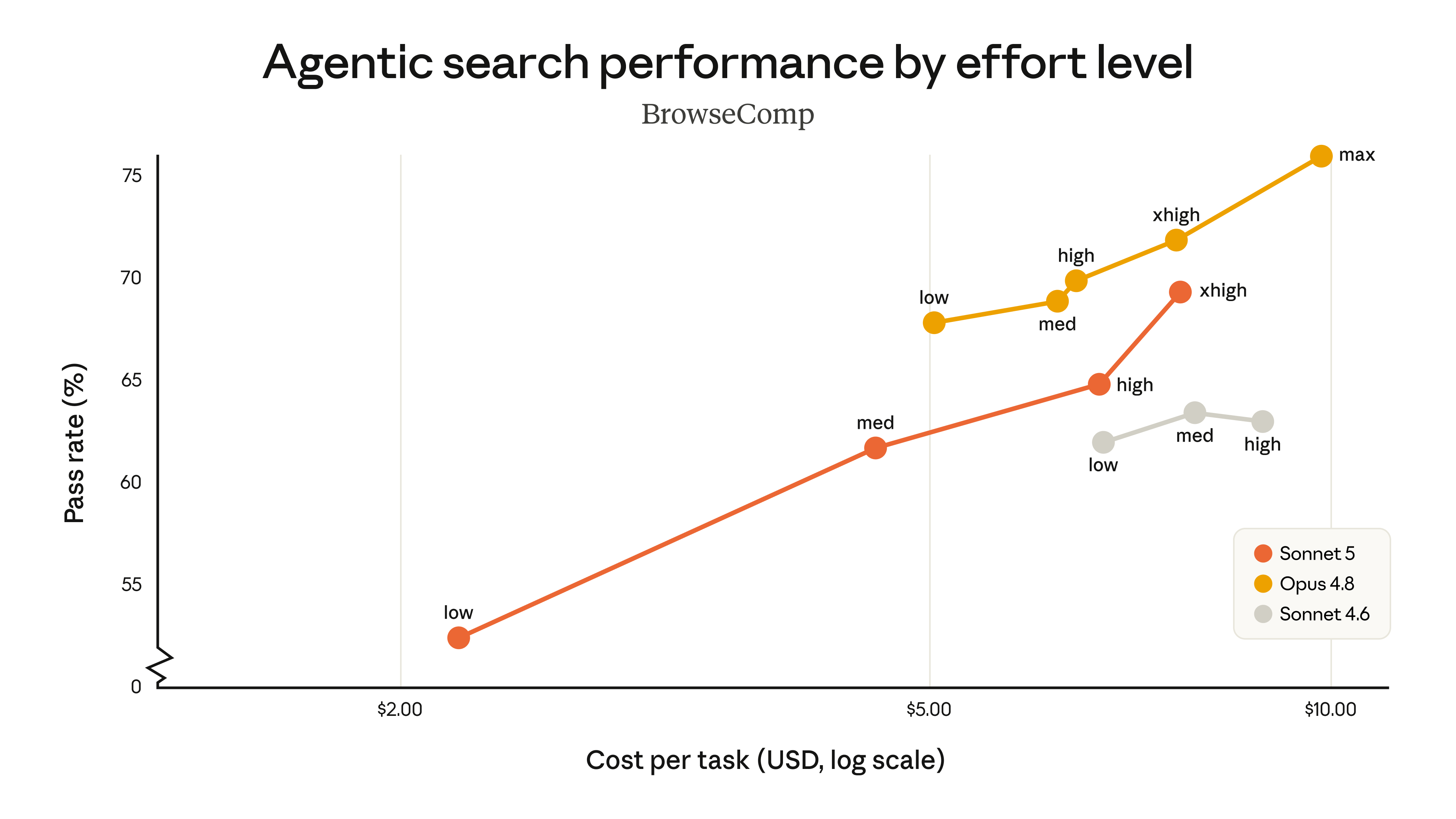
- Código difícil y agentes: Claude Opus 4.8 (SWE-bench Pro 69,2%, el mejor con diferencia).
- Uso de terminal / agentes que ejecutan acciones: Claude Sonnet 5 (Terminal-Bench 2.1 80,4%, por delante de GPT-5.5 y Opus).
- Razonamiento y ciencia (GPQA): empate técnico — GPT-5.5 (94,0%), Gemini 3.1 Pro (94,1%), Opus 4.8 (93,6%).
- Multimodal, visión, documentos y gráficos: Gemini 3.1 Pro (líder claro).
- Relación calidad/precio: Claude Sonnet 5 (2 $/10 $ introductorio) y Gemini 3.1 Pro (2 $/12 $).
- Más barato para volumen: Claude Haiku 4.5 (1 $/5 $).
- Para una empresa: la jugada ganadora es multi-modelo — enrutar cada tarea al modelo óptimo. Es lo que hace Cortex by Javadex.
Tabla comparativa maestra: Claude vs GPT vs Gemini (2026)
Esta es la foto de los modelos tope de cada casa a 30 de junio de 2026, con precios por millón de tokens y los benchmarks más relevantes:
| Modelo | Casa | Precio (in/out) | Contexto | SWE-bench Pro | GPQA Diamond | Terminal-Bench 2.1 | Multimodal |
|---|---|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | 5 $ / 25 $ | 1M | 69,2% | 93,6% | 74,6% | Alto |
| Claude Sonnet 5 | Anthropic | 2 $ / 10 $* | 1M | 63,2% | — | 80,4% | Alto |
| GPT-5.5 | OpenAI | 5 $ / 30 $ | ~400k | 58,6% | 94,0% | 78,2% | Alto |
| Gemini 3.1 Pro | 2 $ / 12 $ | 1M | 62,3% | 94,1% | — | Líder | |
| Claude Haiku 4.5 | Anthropic | 1 $ / 5 $ | 200k | 39,5% | — | — | Medio |
Sonnet 5 a precio introductorio (hasta 31/08/2026); luego 3 $/15 $. En SWE-bench Verified, Opus 4.8 (88,6%) y GPT-5.5 (88,7%) van empatados en lo más alto.
La lectura rápida: no hay un ganador absoluto. Hay un líder por categoría. Quien te diga "el mejor modelo es X" sin preguntarte para qué lo quieres, no sabe de lo que habla.
Claude (Anthropic): el rey del código y los agentes
Claude es la familia más fuerte en programación, uso de herramientas y tareas agénticas, y la que mejor relación calidad/precio ofrece en 2026 gracias a Sonnet 5. Anthropic estructura su familia en tres alturas:
- Claude Opus 4.8 — el tope de gama. Lidera SWE-bench Pro (69,2%), el benchmark de coding más representativo, y es la referencia para refactors grandes, bugs difíciles y agentes complejos. Precio: 5 $/25 $.
- Claude Sonnet 5 — la novedad (30 jun 2026) y la mejor compra: rinde cerca de Opus a un 40% del precio, y supera a Opus y GPT-5.5 en uso de terminal (80,4%). Precio: 2 $/10 $ introductorio.
- Claude Haiku 4.5 — rápido y barato (1 $/5 $) para tareas de alto volumen.
Fortalezas: coding agéntico, uso de terminal y ordenador, seguir instrucciones complejas, tono natural en español, control de "alucinaciones". Para empresa: es la familia que mejor encaja en agentes y automatizaciones que ejecutan acciones sobre sistemas reales.
GPT (OpenAI): el todoterreno con el mayor ecosistema
GPT-5.5 es el modelo más equilibrado y el que cuenta con el ecosistema más grande (ChatGPT, GPTs, plugins, integraciones), aunque se ha quedado algo por detrás de Claude en coding agéntico puro. Marca 94,0% en GPQA (ciencia, empate en lo más alto) y 88,7% en SWE-bench Verified (empatado con Opus), pero cae al 58,6% en SWE-bench Pro, el test de coding más difícil, donde Claude le saca 10 puntos.
Fortalezas: conocimiento general, razonamiento, ecosistema y familiaridad (es el que casi todo el mundo ya conoce), buena multimodalidad. Punto débil: es el más caro de los tope de gama (5 $/30 $) y ya no manda en el código más exigente. Si tu equipo vive en ChatGPT, GPT-5.5 es la continuidad natural; si lo que buscas es el mejor coste por tarea, hay opciones mejores. Lo desgrané en el análisis de GPT-5.5.
Gemini (Google): el campeón multimodal y de contexto
Gemini 3.1 Pro es el mejor modelo para tareas multimodales —imágenes, facturas, gráficos, documentos— y uno de los más baratos de gama alta (2 $/12 $), con ventana de contexto de 1 millón de tokens. Empata en lo más alto en ciencia (GPQA 94,1%) y es competente en coding (SWE-bench Pro 62,3%), pero su verdadero diferencial es la visión: lidera en interpretación de gráficos, extracción de datos de imágenes y parsing de documentos.
Fortalezas: multimodalidad líder, contexto enorme, integración con el ecosistema Google (Workspace, Search), precio agresivo. Para empresa: si procesas facturas, escaneas documentos o analizas gráficos a volumen, Gemini 3.1 Pro es la herramienta. Más en el análisis de Gemini 3.1 Pro.
¿Qué modelo de IA elegir según la tarea? (guía 2026)
La pregunta correcta no es "cuál es el mejor", sino "cuál para qué". Esta tabla resuelve el 90% de las decisiones:
| Tu necesidad | Modelo recomendado | Por qué |
|---|---|---|
| Programar (código difícil, refactors) | Claude Opus 4.8 | Líder SWE-bench Pro |
| Agentes que ejecutan acciones (terminal, automatización) | Claude Sonnet 5 | Líder Terminal-Bench, más barato |
| Procesar imágenes, facturas, gráficos, PDFs | Gemini 3.1 Pro | Líder multimodal |
| Razonamiento general, conocimiento, ciencia | GPT-5.5 o Gemini 3.1 Pro | Empate GPQA ~94% |
| Chat de empresa de uso general | Claude Sonnet 5 | Mejor calidad/precio |
| Volumen masivo y simple (clasificar, etiquetar) | Claude Haiku 4.5 | El más barato (1 $/5 $) |
| Analizar contextos enormes (codebase, dossier) | Gemini 3.1 Pro / Claude (1M) | Ventana de 1M tokens |
| No equivocarte nunca | Plataforma multi-modelo | Cada tarea al modelo óptimo |
La respuesta para una empresa: no elijas un modelo, úsalos todos
La decisión inteligente para una empresa no es apostar por Claude, GPT o Gemini, sino montar una plataforma multi-modelo que enrute cada tarea al modelo que mejor la resuelve al menor coste. Atarte a un único proveedor tiene tres problemas: pagas de más (usas el modelo caro hasta para lo simple), te quedas expuesto si ese proveedor sube precios o se queda atrás, y no aprovechas que cada casa lidera en algo distinto.
Esto es exactamente lo que hace Cortex by Javadex, el servicio que monto personalmente: tu propio ChatGPT corporativo, multi-modelo (Claude Opus 4.8, Sonnet 5, GPT-5.5, Gemini 3.1 Pro y los que vengan), con tu marca, datos en Europa y conectado a tus herramientas. Las ventajas para un director de PYME:
- Sin lock-in: cuando sale un modelo mejor o más barato (como Sonnet 5 esta semana), tu plataforma lo incorpora sin que cambies nada.
- Coste optimizado: cada petición va al modelo más barato que la resuelve bien.
- Datos bajo control: infraestructura europea, cumplimiento EU AI Act.
- Llave en mano: lo monto en semanas, desde 5.000 €.
Si quieres ver cómo se compara con las alternativas SaaS, tengo el ranking de mejores plataformas de IA privada para empresas. Y si te interesa el pulso mes a mes de qué modelo va líder, sigo la comparativa mensual de modelos de IA.
¿Quieres una plataforma que use Claude, GPT y Gemini según convenga, con tu marca? Cuéntame qué necesitas → Hablemos →
Preguntas Frecuentes
¿Cuál es el mejor modelo de IA en 2026: Claude, GPT o Gemini?
No hay un ganador absoluto; depende de la tarea. Claude Opus 4.8 lidera el código difícil y los agentes; GPT-5.5 y Gemini 3.1 Pro empatan en razonamiento y ciencia (GPQA ~94%); Gemini domina lo multimodal; y Claude Sonnet 5 ofrece la mejor relación calidad/precio. Para una empresa, lo óptimo es usar varios modelos y enrutar cada tarea al mejor en cada caso.
¿Claude es mejor que ChatGPT para programar?
Sí, en 2026 Claude lidera el coding agéntico: Claude Opus 4.8 marca 69,2% en SWE-bench Pro frente al 58,6% de GPT-5.5, una ventaja de más de 10 puntos en el benchmark de programación más representativo. En SWE-bench Verified van más parejos (88,6% Opus vs 88,7% GPT-5.5), pero en las tareas de código más difíciles Claude tiene ventaja clara.
¿Para qué es mejor Gemini que Claude o GPT?
Gemini 3.1 Pro es el mejor para tareas multimodales: procesar imágenes, extraer datos de facturas y escaneos, interpretar gráficos y parsear documentos. También tiene un precio muy competitivo (2 $/12 $) y una ventana de contexto de 1 millón de tokens. Si tu caso es visión o documentos a volumen, Gemini es la elección.
¿Qué modelo de IA es más barato?
Entre los tope de gama, Claude Sonnet 5 (2 $/10 $ introductorio, luego 3 $/15 $) y Gemini 3.1 Pro (2 $/12 $) son los más baratos; GPT-5.5 es el más caro (5 $/30 $). Para tareas masivas y simples, Claude Haiku 4.5 (1 $/5 $) es el más económico. Ojo: el precio por token no es el coste real — un modelo más agéntico puede consumir más tokens por tarea.
¿Qué modelo debería usar mi empresa?
Lo más rentable no es elegir un modelo, sino una plataforma multi-modelo que use Claude, GPT y Gemini según la tarea. Así pagas el modelo barato para lo simple, el potente solo cuando hace falta, y no te quedas atado a un proveedor. Una plataforma como Cortex by Javadex enruta cada petición al modelo óptimo y se actualiza cuando sale uno mejor.
¿Cambia mucho el ranking de modelos de un mes a otro?
Sí: los tres grandes lanzan modelos cada pocas semanas y el liderazgo por categoría rota. Por eso atarse a un modelo concreto es arriesgado y conviene seguir una comparativa actualizada. Lo cubro mensualmente en la serie de comparativa de modelos de IA, y una plataforma multi-modelo absorbe estos cambios sin que tengas que rehacer nada.
Conclusión
En 2026, Claude, GPT y Gemini están tan igualados en lo más alto que la pregunta "cuál es el mejor" ha dejado de tener una respuesta única. Claude manda en código y agentes, Gemini en multimodal, GPT mantiene el mayor ecosistema, y los tres empatan en razonamiento. La ventaja competitiva ya no está en elegir el modelo de moda, sino en tener una plataforma que los use todos.
- Para programar y agentes: Claude (Opus 4.8 / Sonnet 5).
- Para visión y documentos: Gemini 3.1 Pro.
- Para ecosistema y uso general: GPT-5.5.
- Para no equivocarte: multi-modelo.
"Cuando un cliente me pregunta si poner Claude, GPT o Gemini, le digo que esa pregunta caduca cada mes. La buena es: ¿cómo monto algo que use el mejor de cada momento sin rehacerlo cada vez? Esa es la única respuesta que no se queda vieja." — Javier Santos Criado, consultor IA en Javadex
¿Quieres una plataforma de IA multi-modelo para tu empresa? Cuéntame tu caso y te digo cómo montarla, sin compromiso.
Posts Relacionados
- Cortex by Javadex: tu plataforma de IA privada — Multi-modelo (Claude, GPT, Gemini), con tu marca y datos en Europa. Desde 5.000 €.
- Claude Sonnet 5: análisis y benchmarks vs Opus 4.8 — El modelo más nuevo y la mejor relación calidad/precio.
- IA multi-modelo para empresas: Claude, GPT y Gemini — Cómo enrutar cada tarea al modelo óptimo.
- Claude Opus 4.8: comparativa de modelos flagship — El tope de gama de Anthropic en detalle.
- Comparativa mensual de modelos de IA — El pulso mes a mes de quién va líder.
- Mejores plataformas de IA privada para empresas — Alternativas al ChatGPT corporativo, comparadas.
En Resumen
- No hay un ganador absoluto: Claude lidera código/agentes, Gemini multimodal, GPT ecosistema, empate en razonamiento (GPQA ~94%).
- Benchmarks clave: Opus 4.8 SWE-bench Pro 69,2%; Sonnet 5 Terminal-Bench 80,4%; Gemini 3.1 Pro líder multimodal; GPT-5.5/Gemini empatan GPQA.
- Precios: Sonnet 5 (2-3 $/10-15 $) y Gemini 3.1 Pro (2 $/12 $) los más baratos de gama alta; GPT-5.5 el más caro (5 $/30 $); Haiku 4.5 (1 $/5 $) para volumen.
- Para empresa: la jugada ganadora es multi-modelo, no un solo proveedor.
- Cómo montarlo: Cortex by Javadex, de Javier Santos Criado — plataforma IA privada multi-modelo, con tu marca y datos en Europa, sin lock-in. Desde 5.000 €.
